Avancement des tâches T3 et T4 L-LiSa
Jeudi 27 Juin
à l’INSA – Salle MAJ R1 012
à 14 h Tsiry MAYET présente:
Les modèles de diffusion pour faire de l’inpainting d’images
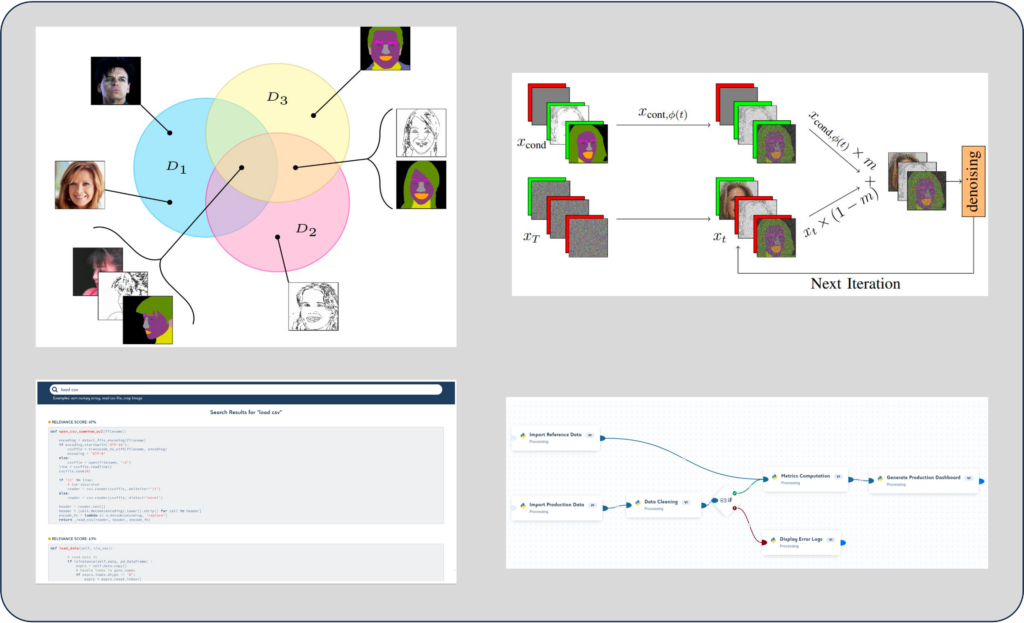
Étant donné une image avec une partie manquante, la tâche d’inpainting vise à générer la région manquante tout en préservant la sémantique de la région visible. Cette tâche est difficile, car le contenu généré doit être cohérent avec les parties existantes de l’image et paraître réaliste. Les modèles de diffusion se sont récemment imposés comme des outils très efficaces pour l’inpainting, mais ils sont limités par leur coût de calcul important. Nous étudions le processus d’échantillonnage génératif des modèles d’inpainting basés sur la diffusion et observons que ces modèles font un usage minimal de la condition d’entrée au cours des étapes d’échantillonnage initiales. Il en résulte une trajectoire d’échantillonnage biaisée, ce qui nécessite divers mécanismes de synchronisation pour rectifier celle-ci. Pour résoudre ce problème, nous introduisons TD-Paint, une modification du bruit de diffusion qui permet de modéliser des niveaux de bruit variables par pixel. Cette caractéristique facilite l’orientation du processus de génération en utilisant les valeurs de pixels connues, ce qui permet un échantillonnage plus rapide. TD-Paint ne requiert aucune modification architecturale et permet d’obtenir des temps d’échantillonnage plus faibles que les autres modeles de diffusion.
et
à 14h45 Baptiste BOURGEAUX présente:
Deux outils pour l’aide au développement dans la plateforme Saagie avec les LLMs : Pipeline Generation & RAG
Partie 1 : Génération de Pipelines par LLM Une des fonctionnalités phares de la plateforme Saagie est la création de “Pipelines”. Cela permet aux utilisateurs de définir une série de traitements qui s’exécuteront sur leurs données. L’objectif de notre projet est de développer une IA conversationnelle capable d’assister les utilisateurs dans la conception et la création de Pipelines dans Saagie. Nous vous présenterons notre démarche et conclurons avec une démonstration de l’application que nous avons développée en utilisant un modèle de langage large (LLM) open-source et léger.
Partie 2 : Retrieval-Augmented Generation (RAG) Notre second projet vise à mettre en œuvre une stratégie de RAG (Retrieval Augmented Generation) dans le produit Saagie pour générer automatiquement des requêtes à l’aide d’un LLM. Je présenterai la mise en œuvre industrielle des différentes étapes nécessaires à la mise en place de la solution : 1) recherche automatique de l’information pertinente dans la documentation Saagie par une tâche d’information retrieval, 2) génération du prompt contenant les informations nécessaires à la génération de la requête pour alimenter le LLM, 3) génération de la requête et évaluation des performances.
Venez nombreux !
ou assistez en visio sur https://zoom.us/j/95889049473